Using FOCA for OSINT Document Metadata Analysis

FOCA, which stands for (Fingerprinting Organizations with Collected Archives) is a pretty nifty tool I use for collecting documents from a target domain and analyzing metadata found within them. Some may argue there are other tools that do this better, and that may very well be true. However, I like the interface for FOCA and because it is run on a Windows system it has a relatively low barrier for learning how to use it.
FOCA runs searches on your domain through Google, Bing, and DuckDuckGo, looking for various filetypes including doc, pdf, xls, Powerpoint, and even Adobe. The metadata extracted from these files may serve to provide additional pivot points for an investigation. Often, FOCA will pull things like usernames, emails, technologies used, and sometimes even business relationships/partnerships from the documents found.
This guide is meant to provide the steps for installing FOCA on a Windows system along with how to extract the data and some tips on how to use the information once extracted.
Installation
Begin by downloading FOCA from the Eleven Paths website (I am using version 3.4.0.6). Once the download is finished, open up the bin folder and double-click the FOCA icon to install the program.

You may get an error message at this point because FOCA requires a SQL server to run but we can take care of this easily by installing SQL Server Express.

Once SQL Server Express is installed, try running the application again and it should work properly.
When FOCA opens we see three main panels, the first panel on the left that will show the documents found, the second and main panel that has spots to add the project name and the domain(s) we plan to search for, and the bottom panel that will show time and source as the search runs.

For this example, my target domain was Xfinity.com which I chose for no other reason than I thought they may have a lot of available documents that would be easy to redact. I added xfinity.com in the main panel inside the box labeled “Domain Website”, then hit create. Be sure to change the save location to where you want the data extracted. In this window we can also add a project name and any additional domains if so inclined.


Once the project has been saved successfully, the main search panel opens. FOCA has many tools for domain recon, some noisier than others, but we are simply looking to analyze metadata as quietly as possible so we will stick to just FOCA searches. Begin by clicking on Settings in the bottom left corner to check/uncheck options.
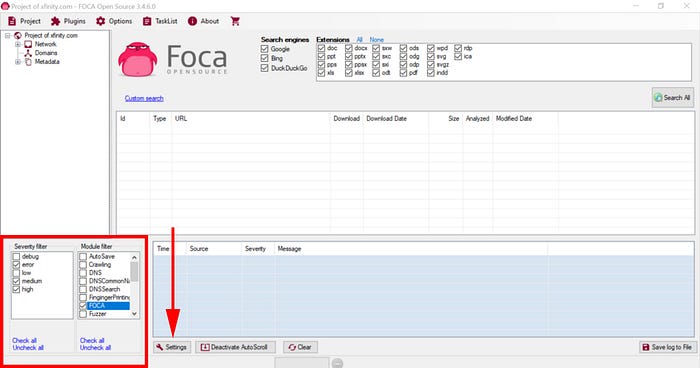
Under Module Filter, uncheck everything but FOCA. This will limit our search to only FOCA and keep the search passive.
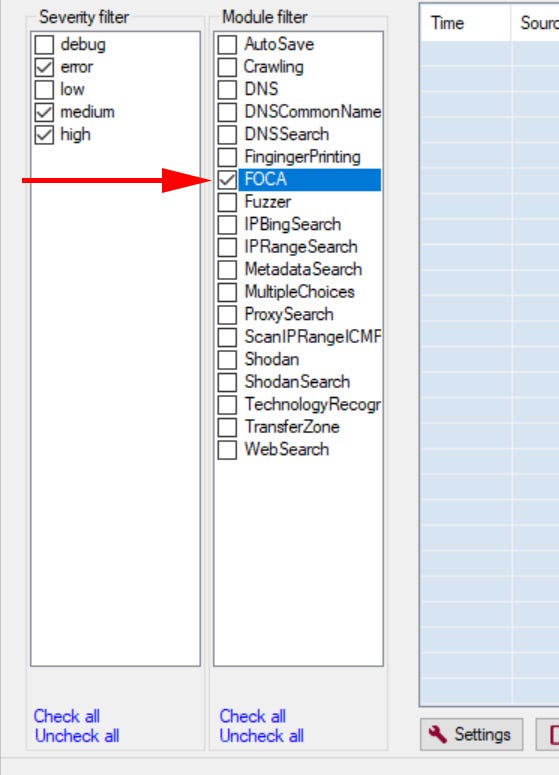
If we head back up to the top of the page, there is the option to select which search engines and what document types we want FOCA to search for. Generally, I just go with everything because I want to gather as much info as possible and analyze it down but if you knew you needed something specific like only Excel files you could narrow the search here.
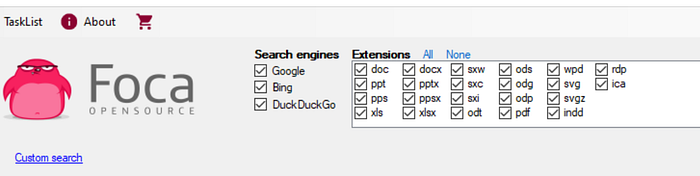
If you prefer to manually adjust your search, click in the search bar and this will allow you to edit the boolean string to your liking.

Now that we have all our settings locked in we can click “search all” and FOCA will begin running through the targeted domain looking for the selected documents. In the image below we see the main panel start to populate with the documents that have been found. It is important to note here that you can also upload your own files to FOCA for metadata extraction. This is handy if you found documents elsewhere and you just want to check out what data is hidden inside.
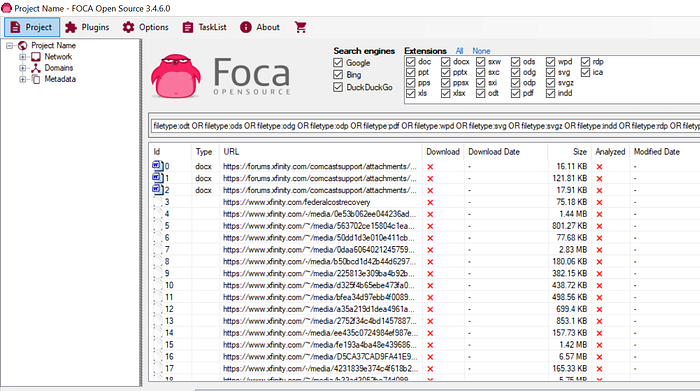
When the search completes, we need to download all of the documents so that we can extract the metadata. In order to do this, right-click on the Download header and select “Download All.”
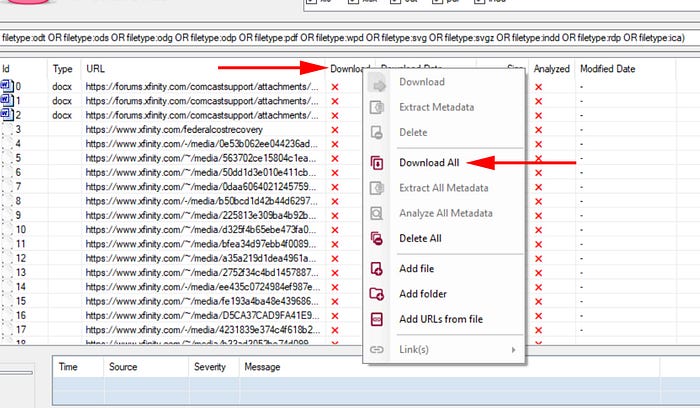
This will run through all of the documents that we have downloaded and the dot beside them will turn green when finished.
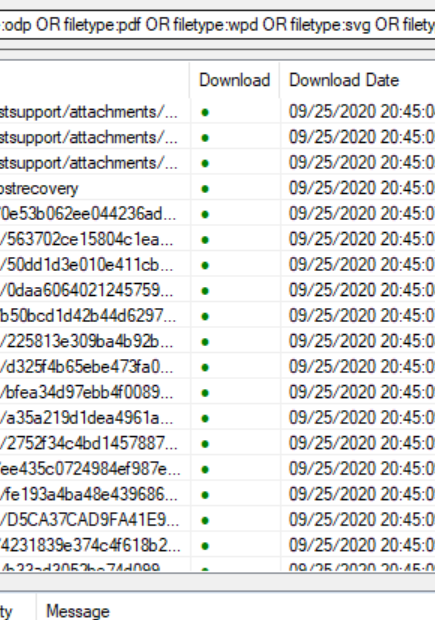
Once we have the results, right-click on the download header again and this time go to “Extract All Metadata.”
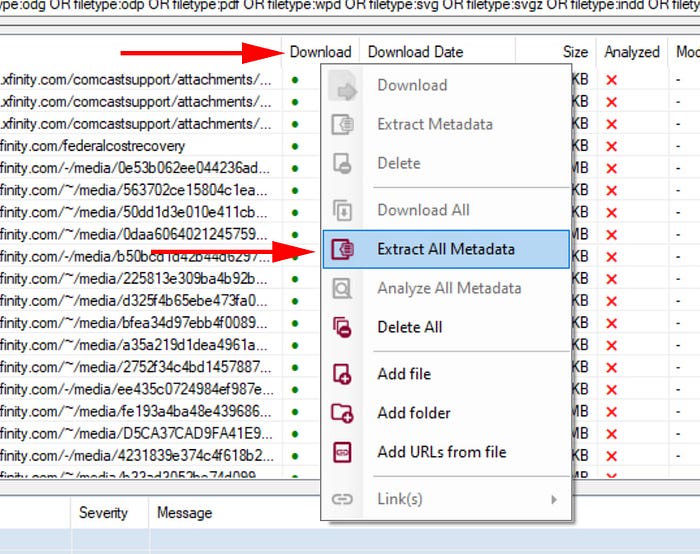
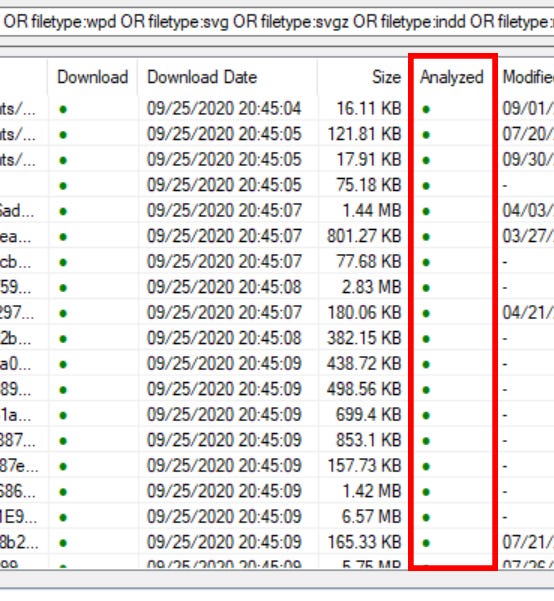
Under the Analyzed column all the dots will turn green when the metadata has been successfully extracted.
Looking now at the list of items in the left panel, click the Metadata drop-down and open Metadata Summary.

FOCA pulls the following data: Users, Folders, Printers, Software, Email, Operating Systems, Passwords, and Servers. Looking at our specific documents, we found: 3 word documents, 80 pdfs, and 47 unknown files were found and within these files are 16 users and 31 software types.
I like to start with usernames because they can usually provide a wealth of information about an organization. Users or Usernames are the names of people who have created or edited the documents we found and their username was saved within the metadata.
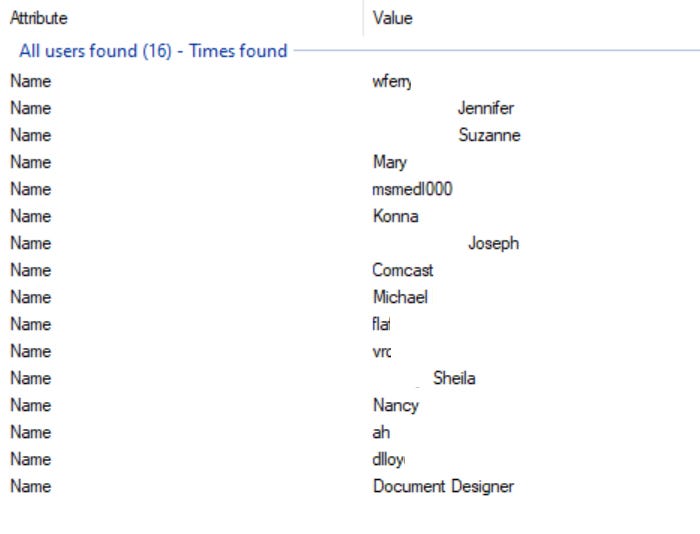
“Users” can be something like a first and last name or it could be a username that I would grab and drop into Sherlock or What’s My Name to see if they were used on any other platforms. First and last names are useful to search in LinkedIn where we can potentially find job titles, resumes, and responsibilities.
The software found category is pretty straightforward, it is all the software used to create the documents. Sometimes the software may have vulnerabilities that could be leveraged by someone with less than stellar motives so it is worth noting any associated CVE’s.
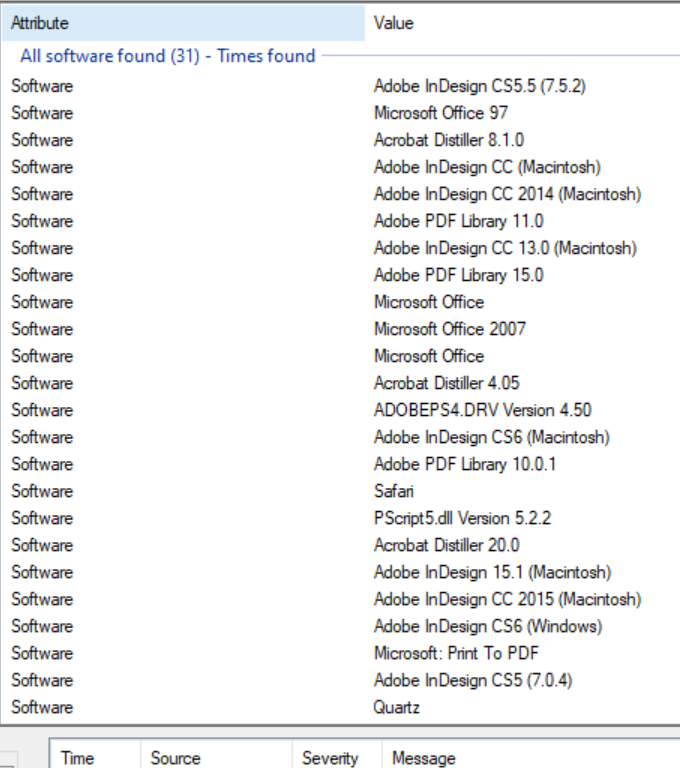
CVE’s aside, the software list might give you an idea of the internal workings of the company when combined with the URLs found within the document list.
Pivoting now to the list of documents we found, it is important to analyze them thoroughly. Many times it is possible to find sensitive documents that shouldn’t be public-facing or that may indicate an important business relationship worth investigating further.
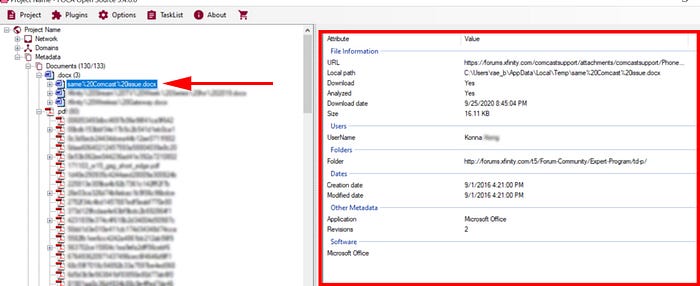
Clicking on the document name in the list on the left opens information in the right panel that shows the specific metadata, dates, software, and any other data found for that particular document.
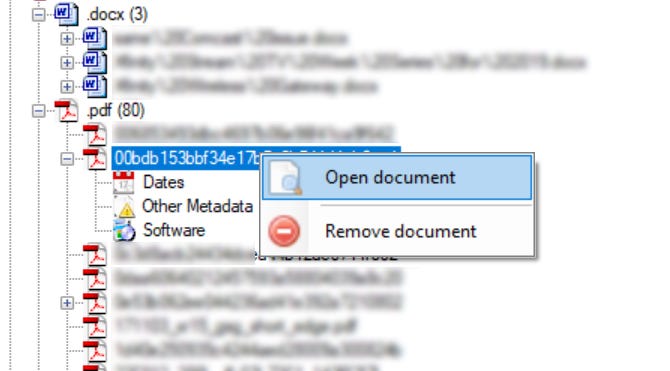
Right-click on the document and select “Open Document” which will then open the document in the associated program. Depending on what type of site you are investigating consider what you may be opening on your machine.
Some of the data that may be found within documents could be names, business relationships, contracts/grants, research projects, intellectual property, blueprints/schematics, etc.
Combining all of the data points (software, users, document paths, document information) pulled from a quick FOCA search, we can get a pretty good inside view of a company or organization and plenty of pivot points to build off of with additional social media, resumes, and corporate recon work.
